glm-5.2 web design Just Beat Claude Fable 5.

An open-weights model topped the Design Arena web design leaderboard for the first time, beating the closed frontier at a sixth of the cost. glm-5.2 web design is Next Level.
On June 20, 2026, something happened that the closed AI labs have been quietly dreading. GLM-5.2, the open-weights model from Z.ai, climbed to first place on Design Arena’s single-round HTML web design leaderboard, beating Claude Fable 5, Opus 4.7, and Opus 4.6 to claim the top spot. An open model you can download for free is now, by at least one respected human-voted benchmark, the best AI in the world at generating web design.
That is a genuinely big deal, and not for the reason most headlines suggest. The story is not “open beat closed” as a one-time scoreboard event. The story is what it means for anyone who builds front-end interfaces with AI, because the model that just won is also the one you can run yourself, plug into your coding agent today, and use at a fraction of what the frontier charges.
But there is an asterisk on this win that the breathless coverage skips, and it changes how you should read it. Let me walk through exactly what GLM-5.2 won, the catch nobody is highlighting, why it designs so well, and whether you should actually switch your front-end workflow to it.
What GLM-5.2 Actually Won
Design Arena is worth understanding before you weigh the result, because the type of benchmark matters enormously here.
Most AI benchmarks are synthetic. A model answers a fixed set of problems and gets scored against known-correct answers. Design Arena works differently. It is a crowdsourced, blind-test platform where real people are shown two AI-generated designs side by side, with the model names hidden, and they vote for the one they prefer. Those millions of pairwise votes produce an Elo rating, the same ranking math used in chess. It is widely regarded as one of the most industry-relevant benchmarks for aesthetics and practical design quality, precisely because it measures what humans actually like rather than what a synthetic test rewards.
On the single-round HTML web design leaderboard, the non-agent category, GLM-5.2 reached number one with an Elo around 1360. That edged out Claude Fable 5, which had been sitting at the top with roughly 1350. It also climbed five positions over its own predecessor, GLM-5.1. So this is both a win over the closed frontier and a real generational jump for Z.ai’s own line.
The win extends beyond that one leaderboard. On the separate Code Arena Frontend ranking, also human-voted, GLM-5.2 in its Max mode sits at number two overall, behind only Fable 5, and ahead of Claude Opus 4.7 by 29 points. It ranks second in the React sub-category and fourth in HTML. Across design specializations like brand marketing, data analytics, gaming, consumer product, and simulation, it earns top-tier placements. Among open models specifically, it beats rivals like Kimi K2.6 and MiniMax-M3 by a wide margin. This is not a fluke in one narrow test. GLM-5.2 is broadly excellent at front-end work.
The Asterisk Nobody Is Highlighting
Here is the part you need to read before you repeat the headline, because the honest version is more useful than the hype.
First, the margin. GLM-5.2’s 1360 Elo over Fable 5’s 1350 is a roughly 10-point gap on the HTML leaderboard. In Elo terms that is close, well within the range where a few hundred more votes or a small model update could flip the order back. This is a fresh, vote-driven ranking, not a settled fact carved in stone. Treat “GLM-5.2 is the best” as “GLM-5.2 is currently at the very top of a tight pack,” because that is what the numbers actually say.
Second, and more important, the leaderboard depends on which view you look at. On the single-round Design Arena HTML benchmark, GLM-5.2 is genuinely first. But on WebDev Arena and some other Code Arena slices that the community also watches, Claude Fable 5 still ranks above it. On one separately-hosted frontend view, Fable 5 sits at 1654 Elo to GLM-5.2’s 1595, though Fable carries a “not currently being sampled” asterisk there, meaning its number may be stale.
So the precise, defensible claim is this: GLM-5.2 is at or near the top of the front-end and design rankings, it clearly leads on the Design Arena HTML benchmark, and across the field it is beaten only by Claude Fable 5, and not even consistently. The most common and most accurate framing in developer communities right now is, “If you exclude Fable, GLM-5.2 is the best front-end model available.” That is a more honest sentence than “GLM-5.2 beats everything,” and it happens to be the more useful one too, for a reason I will get to.
Why GLM-5.2 Designs So Well
The interesting question is not just that it won, but how. Design Arena published an analysis of what GLM-5.2 actually does differently, and the answers are concrete enough to be instructive even if you never touch the model.
The biggest factor is library usage. GLM-5.2 makes efficient use of popular third-party libraries like Chart.js and Three.js. Sessions where it reached for those libraries saw roughly a 6 percentage point improvement in win rate, because pulling in the right tool produces richer, more capable output than hand-rolling everything from scratch.
The second factor is styling discipline. GLM-5.2 uses TailwindCSS in about 91 percent of its sessions and Font Awesome in 51 percent. By comparison, Claude Fable 5 reaches for TailwindCSS in only 57 percent of its sessions. That gap matters, because consistent use of a mature utility-first CSS framework tends to produce cleaner, more coherent layouts than ad hoc styling, and the analysis suggests this is part of why GLM-5.2’s designs win more blind votes. Carefully designed interactions added another 1.2 percentage points to its win rate.
There is also a layout and imagery story. GLM-5.2 shows notably improved layout capability, strong typography and visual hierarchy, and it skillfully incorporates external CDN images into the pages it builds. The result is sites that feel alive, with subtle animations and proper structure, rather than the flat, templated output that AI front-end generation became known for. If you want to improve your own AI-assisted design output, that list doubles as a checklist: lean on good libraries, commit to one styling system, and mind your visual hierarchy.
The Cost Gap Is the Real Headline
This is where the front-end win stops being a leaderboard curiosity and starts changing decisions.
GLM-5.2’s API pricing runs about $1.40 per million input tokens and $4.40 per million output tokens. Claude Fable 5, the model it is trading blows with, runs roughly $10 per million input and $50 per million output. That is not a small difference. Fable is around seven times more expensive on input and more than eleven times more expensive on output, for design quality that human voters rate as comparable or slightly behind.
Now factor in that front-end work is iterative by nature. You generate a layout, tweak it, regenerate, adjust the spacing, try a different component, regenerate again. Each loop burns tokens. At Fable’s pricing, heavy iteration on UI gets expensive fast. At GLM-5.2’s pricing, you can afford to iterate freely, which for design work is not just a cost saving but a creative advantage, because more cheap iterations often beats fewer expensive ones.
There is one token nuance worth knowing. GLM-5.2 offers two thinking modes, High and Max. Max pushes to peak intelligence but burns close to 85,000 output tokens per task. Switching to High sacrifices only a few points of quality while roughly halving the token output. For latency-sensitive or cost-sensitive front-end work, High is often the smarter default, with Max reserved for the genuinely hard generations. That lever is part of why the cost story holds up in practice and not just on the sticker.
Why “Best Practical Model” Beats “Best Model”
Here is the reason the “if you exclude Fable” framing is not a cop-out but the actual point.
Claude Fable 5 is a closed-weights model with restricted availability and rate limits. Most developers cannot simply plug it into their coding agent and ship with it. It is the model people are trying to substitute into their workflows, not one they already have free rein over.
GLM-5.2 is the opposite. It is open-weights under an MIT license, with a 1 million token context window, and it can be run locally or through any of numerous providers. That is exactly why it showed up in Claude Code, OpenCode, Cline, and Roo Code almost immediately after release. Open models are trivial to plug in, so developers adopt them fast, often before they bother integrating a closed flagship.
Put those two facts together and the practical reality is striking. For the large majority of developers who cannot or will not build their production front-end pipeline on a restricted, premium-priced closed model, GLM-5.2 is effectively the best web design AI they can actually use. Not the best in a theoretical leaderboard sense, the best in the sense that matters: available, affordable, runnable, and good enough to win blind human votes against the frontier. That is a more disruptive position than simply topping a chart.
What This Signals About Open Models in 2026
Step back from the single benchmark and the result fits a pattern that has been building all year.
GLM-5.2 is not competing only with other open models anymore. It is challenging the closed frontier directly, the Claude Fable 5, Opus 4.8, GPT-5.5, and Gemini 3.1 Pro tier. Topping a human-voted design benchmark over Fable is the most concrete sign yet that the gap between what you can download and what you have to rent has narrowed to the point of being situational rather than absolute. On some tasks the open model now wins outright.
The design win is especially symbolic because aesthetics were supposed to be the hard part for open models. Raw coding correctness can be drilled with synthetic data, but pleasing human taste in layout, color, spacing, and motion is fuzzier and was assumed to favor the labs with the deepest training budgets. An open-weights model winning blind human design votes punctures that assumption. It suggests the techniques that produce good design, sensible library choices, consistent styling systems, strong layout priors, are now learnable and shippable outside the top three labs.
For the broader market, the takeaway is not that closed models are finished. Fable still leads several leaderboards, and the frontier keeps moving. The takeaway is that “use the open model” is no longer a compromise you justify on cost while wincing at quality. For front-end work specifically, it can now be the quality choice and the cost choice at the same time, which is a combination that did not exist a year ago.
Should You Switch Your Front-End Workflow?
Here is the practical decision, stripped of cheerleading.
Switch to GLM-5.2 for front-end work if you are doing high-volume, iterative UI generation, if cost matters, if you want to run your design pipeline locally or self-hosted for privacy or control, or if you are currently paying Fable or Opus prices for design output that human voters rate as comparable. For most web design and component generation, you will get top-tier results at a fraction of the cost, and the open weights mean no rate limits and no vendor lock-in. Use High mode as your default and save Max for hard generations.
Stay on Claude Fable 5 if your work sits at the absolute top of design difficulty where its slight edge on some leaderboards genuinely pays for itself, or if you are already deep in an Anthropic-based workflow where the integration cost of switching outweighs the savings. Fable still ranks first on WebDev Arena and some frontend slices, so for the most demanding work it remains a defensible choice, just an expensive one.
Run both if you want the smartest setup. Use GLM-5.2 for the bulk of your iteration and generation, where its cost advantage compounds across hundreds of loops, and escalate only your hardest or highest-stakes design tasks to Fable. The price gap is wide enough that even a rough split saves serious money while keeping the frontier on call.
One honest caution. These leaderboards are fresh and vote-driven, and the AI release cycle is measured in weeks. GLM-5.2’s position is strong today, but a new model from another lab or a few thousand more votes could reshuffle the order. Benchmark a real design task from your own work through it before you commit your pipeline. Your output on your projects is the only ranking that decides this for you.
Frequently Asked Questions
Did GLM-5.2 really beat Claude Fable 5 at web design? Yes, on Design Arena’s single-round HTML web design leaderboard, announced June 20, 2026. GLM-5.2 reached number one with an Elo around 1360, edging out Fable 5 at roughly 1350. The margin is small, and on some other leaderboards like WebDev Arena, Fable 5 still ranks higher.
What is Design Arena? It is a crowdsourced, blind-test benchmark where real people compare two AI-generated designs without knowing which model made them and vote for the better one. Those votes produce an Elo ranking. It is valued for measuring real human design preference rather than synthetic test scores.
Is GLM-5.2 the best AI model for front-end development? By the Design Arena HTML benchmark, yes, and it ranks number two on Code Arena Frontend behind only Fable 5. The fair framing is that it is at or near the top, beaten only by Fable and not consistently. For developers who cannot easily access closed models, it is effectively the best usable option.
Why is GLM-5.2 good at web design? Design Arena’s analysis points to efficient use of libraries like Chart.js and Three.js, heavy and consistent use of TailwindCSS (91% of sessions versus Fable’s 57%), strong layout and typography, good visual hierarchy, and skillful use of CDN images and subtle animations.
How much cheaper is GLM-5.2 than Claude Fable 5? GLM-5.2 runs about $1.40 per million input tokens and $4.40 per million output. Fable 5 runs roughly $10 and $50. That makes Fable around seven times pricier on input and over eleven times pricier on output.
What is the difference between GLM-5.2’s High and Max modes? Max pushes maximum intelligence but uses close to 85,000 output tokens per task. High sacrifices only a few points of quality while roughly halving token use. For most front-end work, High is the cost-effective default.
Can I run GLM-5.2 myself for design work? Yes. It is open-weights under an MIT license with a 1 million token context window, and it is already integrated into tools like Claude Code, OpenCode, Cline, and Roo Code. You can run it through a provider or self-host it if you have the hardware.
Ved Vyas
Writer at Fable Knows, covering AI and the technology shaping everyday life.
Related stories.

Seedance 2.5: 5 Powerful Upgrades Confirmed for July 2026
Seedance 2.5 is confirmed: ByteDance revealed 30-second clips, 50 reference inputs, and an early July launch. See every upgrade and what it means. (154…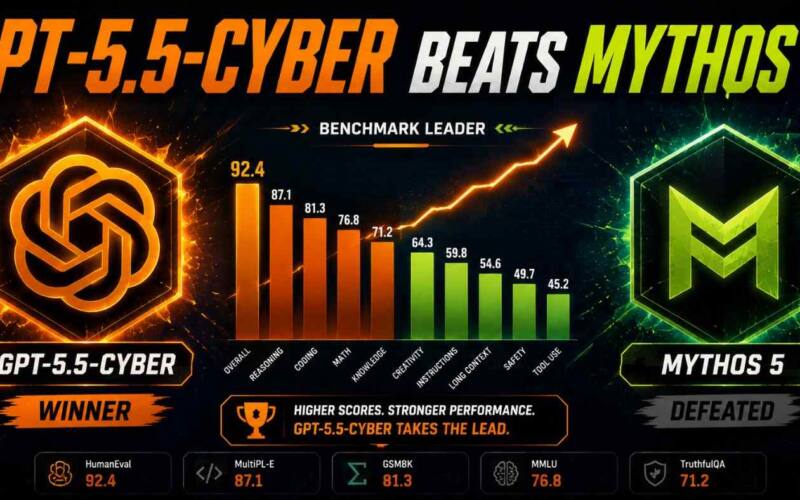
GPT-5.5-Cyber: 7 Powerful Upgrades Beating Mythos 5 in 2026
OpenAI’s GPT-5.5-Cyber model just took back the security crown, and the fixing pipeline matters more than the score. On June 22, 2026, OpenAI stopped…