What Is Sakana Fugu? The AI That Orchestrates GPT, Claude, and Gemini to Beat Them All

Sakana Fugu orchestrates GPT-5.5, Claude, and Gemini behind one API and beats them on hard benchmarks. How it works, what it costs, and when not to use it.
Sakana AI just shipped a model whose entire job is to command other models. It beats Opus 4.8 and GPT-5.5 on hard benchmarks without being a frontier model itself. Here is how it works, where it wins, and the catch worth knowing.
Most of the AI race has been a contest to build the single biggest, smartest model. Sakana Fugu, released by Tokyo-based Sakana AI, is a bet that the race is asking the wrong question. Instead of trying to build a model that beats GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro, Fugu’s whole job is to command them. It is a model that conducts other models like an orchestra, and on several of the hardest engineering and reasoning benchmarks, the orchestra beats every soloist in the room.
That is a genuinely different idea, and the benchmark numbers behind it are strong enough that it deserves more than a press-release rewrite. Fugu Ultra scores 73.7 on SWE-Bench Pro, ahead of Opus 4.8 at 69.2 and GPT-5.5 at 58.6, despite not being a frontier model in the usual sense at all.
Let me explain what Fugu actually is in plain terms, how the orchestration works, what the benchmarks really show, the strategic angle that makes this matter beyond the scores, and the honest cases where you should not use it.
What Sakana Fugu Actually Is
Start with the core idea, because it is unusual and easy to get wrong.
Fugu is not a frontier large language model in the way Claude or GPT is. It is a smaller model, built on a roughly 7-billion-parameter base, whose entire specialty is coordination. It reads your task, breaks it into pieces, decides which powerful external model should handle each piece, writes the prompts for those models, runs them (sometimes one after another, sometimes in parallel, sometimes recursively), and stitches the results into one answer. From the outside you call a single API and get a single response. On the inside, a coordinated team of frontier models did the work.
Sakana describes this as “a multi-agent system, delivered as one model.” The clever part is that Fugu itself is a language model trained specifically to understand delegation: when to hand off, how the agents should talk to each other, and how to combine their outputs into something reliable. It is not a hand-coded rulebook that says “send math to model X and code to model Y.” It learns the coordination patterns itself, and it often finds non-obvious team structures that a human engineer would not have prescribed.
The model pool it conducts includes the publicly available frontier models, the GPT, Claude, and Gemini families. Notably, it does not include Anthropic’s Fable 5 or Mythos Preview, because those are not publicly accessible, so Fugu cannot call them. That detail matters for the benchmark story, as you will see.
Fugu ships in two flavors through one OpenAI-compatible API. Plain Fugu balances quality against latency and is the everyday default, suited to coding tools like Codex, code review, and responsive chatbots. Fugu Ultra coordinates a deeper pool of expert agents to maximize answer quality on hard, high-stakes problems, and early users lean on it for Kaggle competitions, paper reproduction, cybersecurity analysis, and patent research. Ultra trades response time for depth.
How the Orchestration Works
The technology is not vaporware. It is grounded in two papers accepted at ICLR 2026, one of the field’s top venues, and the lineage is worth understanding because it explains why this works.
The first paper, TRINITY, uses a lightweight evolved coordinator that assigns each model in the pool a role: Thinker, Worker, or Verifier. The Thinker reasons through the approach, the Worker executes, and the Verifier checks the result. Crucially these roles are assigned dynamically across multiple turns, so the system adapts the team structure to the specific task rather than using one fixed pipeline for everything.
The second paper, the Conductor, is trained with reinforcement learning to discover coordination strategies in natural language. Rather than engineers hand-designing how agents should communicate, the Conductor learns its own communication patterns and focused prompts that get a diverse pool of models to outperform any single one. In plain terms, it taught itself how to be a good manager of other AIs.
There is a subtle capability that falls out of this design. Because Fugu can read its own intermediate output, it can recognize when its first coordination strategy was weak and spin up a corrective workflow on the fly. Recursion depth becomes something you can dial at inference time without retraining. That self-correction is part of why the orchestrated system holds up on long, messy tasks where a single model tends to drift.
The pedigree behind this is not trivial. Sakana AI was co-founded by David Ha, formerly of Google Brain and Stability AI, and Llion Jones, one of the co-authors of “Attention Is All You Need,” the 2017 paper that introduced the Transformer architecture underpinning essentially every modern LLM. This is a lab that has consistently chased alternatives to brute-force compute scaling, and earlier in 2026 its AI Scientist system became the first AI to have a fully generated paper pass peer review at a machine learning conference, a result that landed in Nature.
The Benchmarks, Read Honestly
The headline numbers are real and they are impressive. But they need context to be useful, so let me give you both.
On SWE-Bench Pro, a demanding software engineering test, Fugu Ultra scores 73.7. That beats Claude Opus 4.8 at 69.2 and GPT-5.5 at 58.6. On TerminalBench 2.1, Fugu Ultra hits 82.1 against Opus 4.8’s 74.6. On LiveCodeBench, both Fugu variants lead, with Ultra at 93.2 versus Gemini 3.1 Pro’s 88.5. On GPQA-Diamond, a hard science-reasoning benchmark, Fugu reaches 95.5, ahead of all three frontier baselines. On Humanity’s Last Exam, Ultra scores 50.0, edging Opus 4.8’s 49.8. Across coding, reasoning, and scientific benchmarks, the orchestrated system repeatedly lands at or near the top.
Here is the context that the cheerleading skips. Sakana’s own comparison says Fugu is “shoulder-to-shoulder with Fable 5 and Mythos Preview,” not clearly ahead of them. And it cannot be otherwise, because those two models are not in Fugu’s pool. So the honest framing is this: Fugu beats the best publicly accessible models you can actually call, and it matches the restricted frontier models it is not even allowed to use. That is a more precise and more interesting claim than “Fugu is the best model in the world,” which it is not claiming to be.
A second honest point. Orchestration adds overhead. Routing a task through a coordinator, calling multiple models, and combining their outputs takes more time and, on complex jobs, can use more total tokens than a single call. The benchmark wins come on hard, multi-step problems where that extra coordination pays off. On simple one-shot queries, the orchestration tax is not worth it, which is exactly why Sakana built the lower-latency plain Fugu tier alongside Ultra.
The Strategic Angle: Frontier Performance Without Export Controls
This is the part that makes Fugu matter beyond a leaderboard, and it is the angle most coverage underplays.
The most powerful AI models have become geopolitical objects. Anthropic’s Mythos-class models were placed under access restrictions tied to export-control directives, and that kind of fencing makes enterprises nervous about building critical systems on a model they might lose access to. Sakana’s pitch leans directly into this. Fugu delivers “frontier capability without the risk of export controls,” because it is not a single restricted artifact. It is a coordination layer over whatever capable models are available to you.
There is a related benefit: no single-vendor dependency. If you build your whole stack on one provider and that provider raises prices, changes terms, suffers an outage, or gets restricted in your region, you are exposed. Fugu sits as a control layer between you and the underlying models, and for the plain Fugu tier you can even opt specific providers or models out of the pool to meet data, privacy, or compliance requirements. For a regulated enterprise, that flexibility can matter more than a few benchmark points.
It also fits a broader industry shift. Independent analysts looking at Fugu have predicted that trained orchestration is where the field is heading, and that the major labs and the popular agent frameworks will ship their own trained routers within a year. Sakana is early to commercializing an idea that is about to get crowded. The orchestration layer is becoming a model in its own right, and Fugu is the cleanest commercial demonstration of it so far.
Pricing and How to Access It
The pricing has a genuinely clever structure that addresses the obvious worry: if Fugu calls several expensive models, does it stack up several expensive bills?
It does not. When only one agent is active, you pay the standard rate for that underlying model. When multiple agents coordinate, Sakana charges a single rate based on the top-tier model involved, rather than summing every model’s fee. So adding more agents to the pool does not multiply your bill. It only determines which single model rate applies.
Fugu Ultra has fixed pricing at $5 per million input tokens and $30 per million output tokens, with cached input at $0.50. Those rates roughly double for contexts above 272,000 tokens, to $10, $45, and $1.00. There is also a subscription path with three tiers: Standard at $20 a month for light daily use, Pro at $100 for ten times that allowance, and Max at $200 for twenty times, aimed at heavy long-running workloads. Every tier includes both Fugu and Fugu Ultra. Sakana is running a launch promotion: subscribe before the end of July 2026 and get a free second month at your tier.
Access is through an OpenAI-compatible API, which is the smart deployment choice. If your code already targets the OpenAI API, you point it at Fugu’s endpoint with your key and start sending requests, no SDK migration needed. That low switching cost is a big part of the appeal.
Two access caveats. Fugu is not available in the EU or EEA while Sakana works toward GDPR compliance, and the routing is a black box by design. You get the answer and a usage report, but Sakana does not expose which specific models it picked or how it coordinated them, since that routing logic is its core proprietary advantage.
When You Should Not Use Fugu
A fair guide has to cover where this does not fit, and there are real cases.
Skip Fugu if you need fully auditable routing decisions. Regulated finance, healthcare, and insurance workflows sometimes require you to show exactly which model made which decision, and Fugu’s routing is intentionally hidden. Skip it if your application is extremely latency-sensitive, the kind of sub-100-millisecond response where the orchestration overhead is a dealbreaker. Skip it if you already run a hand-tuned orchestration workflow that works well for your specific task distribution, since a general learned router may not beat a setup you have already optimized by hand. And of course, skip it for now if you operate in the EU or EEA, where it is not yet available.
Fugu shines on the opposite profile: complex, multi-step tasks where answer quality matters more than raw speed, teams that want frontier-level results without betting everything on one vendor, and anyone who wants to plug orchestrated intelligence into an existing OpenAI-compatible setup with minimal work. Match it to that profile and it is compelling. Force it onto simple, latency-critical, or audit-heavy workloads and it is the wrong tool.
Frequently Asked Questions
What is Sakana Fugu? Sakana Fugu is an AI product from Tokyo-based Sakana AI that works as a single model but actually orchestrates a pool of frontier models like GPT-5.5, Claude, and Gemini behind one API. A smaller coordination model reads your task, splits it up, assigns pieces to the best models, and combines the results into one answer.
How is Fugu different from just using GPT-5.5 or Claude? Instead of relying on one model for everything, Fugu dynamically assembles a team of models per task and coordinates them. On hard, multi-step benchmarks this orchestrated approach beats any single frontier model it can call, though it adds some latency and is overkill for simple queries.
Does Fugu actually beat frontier models? On benchmarks it can call from, yes. Fugu Ultra scores 73.7 on SWE-Bench Pro versus Opus 4.8’s 69.2 and GPT-5.5’s 58.6, and leads on TerminalBench, LiveCodeBench, and GPQA-Diamond. Against the restricted Fable 5 and Mythos Preview, which it cannot use, Sakana describes it as shoulder-to-shoulder rather than ahead.
What is the difference between Fugu and Fugu Ultra? Fugu balances quality and low latency, making it the everyday default for coding and interactive work. Fugu Ultra coordinates a deeper pool of agents for maximum quality on hard problems like paper reproduction and Kaggle competitions, at the cost of slower responses.
How much does Sakana Fugu cost? Fugu Ultra is priced at $5 per million input tokens and $30 per million output, with cached input at $0.50, roughly doubling above 272K-token contexts. Subscriptions run $20, $100, or $200 per month. When multiple models are coordinated, you pay a single rate based on the top-tier model, not stacked fees.
Who is behind Sakana AI? Sakana AI is a Tokyo lab co-founded by David Ha, formerly of Google Brain and Stability AI, and Llion Jones, a co-author of the original Transformer paper “Attention Is All You Need.” The lab focuses on alternatives to brute-force compute scaling.
Can I use Fugu in the EU? Not currently. Fugu is unavailable in the EU and EEA while Sakana works toward GDPR compliance. It is accessible from most other regions, subject to local regulations and network conditions.
Why does the export-control angle matter? Because the most powerful models can be restricted by access and export directives, building on a single restricted model is risky for enterprises. Fugu offers frontier-level performance as a coordination layer over available models, avoiding dependence on any one restricted artifact.
Ved Vyas
Writer at Fable Knows, covering AI and the technology shaping everyday life.
Related stories.

Seedance 2.5: 5 Powerful Upgrades Confirmed for July 2026
Seedance 2.5 is confirmed: ByteDance revealed 30-second clips, 50 reference inputs, and an early July launch. See every upgrade and what it means. (154…
GPT-5.5-Cyber: 7 Powerful Upgrades Beating Mythos 5 in 2026
OpenAI’s GPT-5.5-Cyber model just took back the security crown, and the fixing pipeline matters more than the score. On June 22, 2026, OpenAI stopped…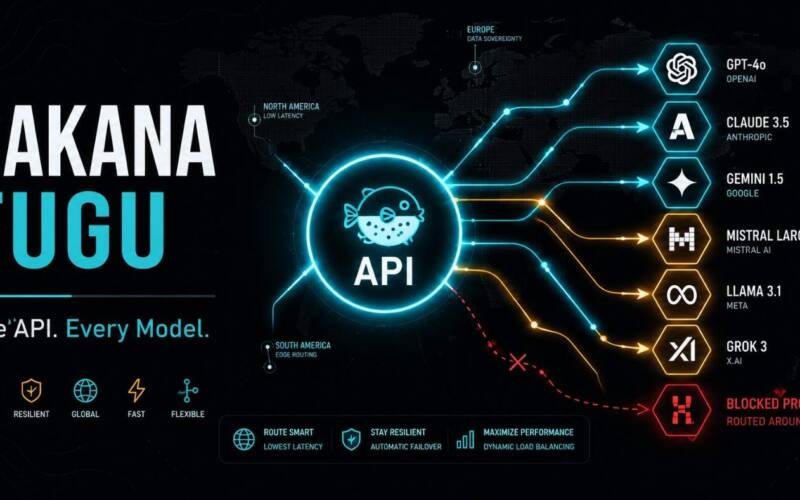
Fascinating how AI is evolving. Do you think Fable really has an edge over the others?
[…] Sakana Fugu is a multi-agent orchestration system that behaves like a single foundation model. You send a request to one OpenAI-compatible endpoint, and Fugu decides how to handle it. Easy questions get answered on the spot. Hard, multi-step problems trigger something different: Fugu assembles a team of expert models, hands one the planning, another the execution, another the verification, then synthesizes everything into one clean answer. None of that coordination ever leaks into your code. […]