Sakana Fugu: 7 Powerful Facts About the Orchestration Model
Explore Sakana Fugu, the 2026 orchestration model that routes around export controls. Get Fugu vs Fugu Ultra benchmarks, pricing, and who should use it. (152 chars, keyword inside, action verb + payoff)
On June 22, 2026, a Tokyo lab skipped the usual playbook. Instead of shipping a bigger model, Sakana AI shipped a smarter conductor. Sakana Fugu is one API that quietly commands a pool of the world’s strongest models, and it arrived ten days after the news that made it matter.
Here is the honest version of what launched, what the numbers actually say, and whether the headline pitch survives contact with reality.
What Is Sakana Fugu?
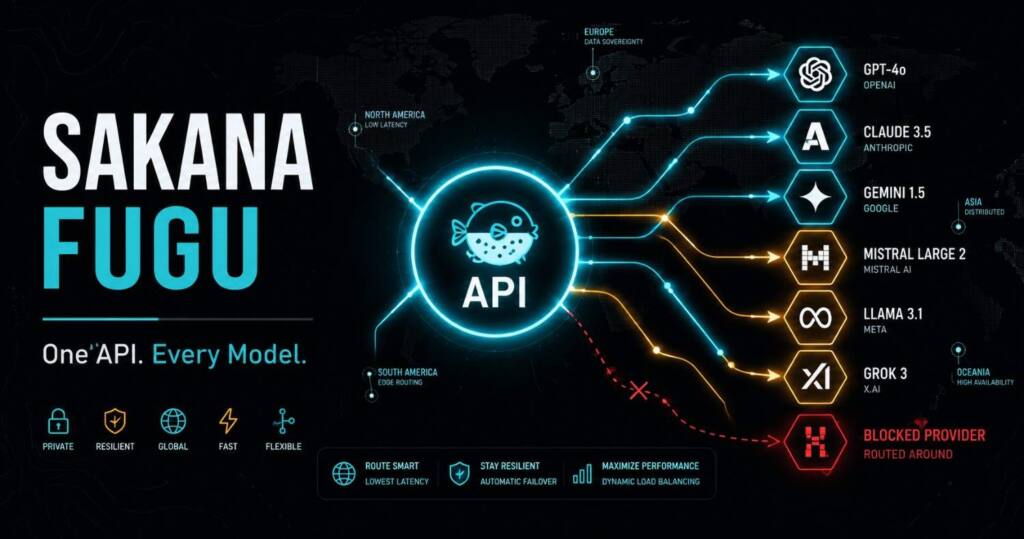
Sakana Fugu is a multi-agent orchestration system that behaves like a single foundation model. You send a request to one OpenAI-compatible endpoint, and Fugu decides how to handle it. Easy questions get answered on the spot. Hard, multi-step problems trigger something different: Fugu assembles a team of expert models, hands one the planning, another the execution, another the verification, then synthesizes everything into one clean answer. None of that coordination ever leaks into your code.
What separates Sakana Fugu from a router you might wire up yourself is that the orchestration is learned, not hardcoded. Fugu is itself a language model, trained to understand when to delegate, how agents should talk to each other, and how to fold their outputs into a reliable result. There is no if/else logic mapping keywords to models. The model decides.
That distinction is the whole story. Anyone can build a switch statement that sends code to one API and math to another. Teaching a model to discover non-obvious collaboration patterns on its own is a different kind of problem, and it is the one Sakana spent years on.
The system ships in two flavors, both behind the same API: a balanced everyday model and a flagship called Fugu Ultra. More on the split below.
How Sakana Fugu Works: A Model That Commands Other Models
The mechanism is the part worth slowing down on. Sakana Fugu is grounded in two peer-reviewed papers accepted at ICLR 2026, which is what keeps this from being prompt engineering dressed up as a product.
The first paper, TRINITY, describes a lightweight evolved coordinator that assigns three roles across a model pool: Thinker, Worker, and Verifier. It adaptively delegates work across coding, math, reasoning, and knowledge tasks, deciding on the fly which model is best suited to each slice. The second paper, the Conductor, goes further. It is trained with reinforcement learning to discover natural-language coordination strategies, effectively learning how agents should communicate and what focused prompts make a diverse pool outperform any single member.
Productized together, those two ideas become one endpoint that handles selection, delegation, verification, and synthesis on your behalf.
There is one more architectural detail that I find genuinely clever. Fugu can call instances of itself recursively. It can decompose a hard task, spin up a fresh copy of itself to manage a sub-problem, solve that, then verify and stitch the pieces back together. That recursion enables a form of test-time scaling: when a first attempt falls short, Fugu reads its own prior output and launches a corrective pass. The machinery never surfaces in your request. You called one model. Inside, a coordinated system of specialists did the work.
The practical payoff is compounding. Because the orchestration is learned rather than fixed, the system improves as the pool improves. When a stronger model enters the agent pool, Fugu folds it in and passes the gains to you, with zero changes to your integration. You moved from running your own servers to a managed cloud, except the thing being managed is intelligence routing, not infrastructure.
Fugu vs Fugu Ultra: Which One You Actually Need
At launch, Sakana Fugu comes in two tiers. Picking between them is mostly a question of how deep a pool you need and how much latency you can spend.
| Fugu | Fugu Ultra | |
|---|---|---|
| Optimized for | Balance of speed and quality | Maximum answer quality |
| Best for | Coding, code review, chatbots | Research, security, deep analysis |
| Agent pool | Configurable, opt agents out | Fixed full pool |
| Latency | Low | Higher |
| Pool control | Yes, exclude providers | No |
Fugu is the everyday default. It balances strong performance with low latency, drops cleanly into tools like Codex for coding and review, and powers responsive chatbots. If your team has data, privacy, or compliance constraints, Fugu lets you opt specific agents out of its pool, which is a real enterprise lever rather than a checkbox.
Fugu Ultra is the heavy hitter. It coordinates a deeper pool of expert agents and is tuned for hard, high-stakes, multi-step problems. Early users reached for it on Kaggle competitions, paper reproduction, cybersecurity analysis, and patent investigations. The tradeoff is speed and cost, so it is not the model you run on every interactive request.
One counterintuitive finding from the benchmark table: on a few tests like SciCode, the balanced Fugu actually scores higher than Fugu Ultra. More orchestration is not always better. That is a useful reminder that the deeper pool is a tool for specific kinds of difficulty, not a blanket upgrade.
My rule of thumb: default to Fugu, and reserve Fugu Ultra for tasks that are genuinely long-horizon and where a wrong answer is expensive.
Sakana Fugu Benchmarks: Strong, but Not a Clean Sweep
This is where the marketing and the spreadsheet start to diverge, so read carefully.
Sakana published results across eleven engineering, scientific, and reasoning benchmarks, comparing both Fugu models against publicly accessible frontier systems: Opus 4.8, Gemini 3.1 Pro, and GPT-5.5. Here is a slice of the headline numbers Sakana Fugu reported.
| Benchmark | Fugu | Fugu Ultra | Opus 4.8 | Gemini 3.1 Pro | GPT-5.5 |
|---|---|---|---|---|---|
| SWE-Bench Pro | 59.0 | 73.7 | 69.2 | 54.2 | 58.6 |
| TerminalBench 2.1 | 80.2 | 82.1 | 74.6 | 70.3 | 78.2 |
| LiveCodeBench | 92.9 | 93.2 | 87.8 | 88.5 | 85.3 |
| Humanity’s Last Exam | 47.2 | 50.0 | 49.8 | 44.4 | 41.4 |
| GPQA-D | 95.5 | 95.5 | 92.0 | 94.3 | 93.6 |
| MRCRv2 | 86.6 | 93.6 | 87.9 | 84.9 | 94.8 |
On its flagship coding test, SWE-Bench Pro, Fugu Ultra lands at 73.7, ahead of Opus 4.8 at 69.2, GPT-5.5 at 58.6, and Gemini 3.1 Pro at 54.2. It also leads on LiveCodeBench, TerminalBench, and edges Opus 4.8 on Humanity’s Last Exam by a hair, 50.0 against 49.8.
But the wins are not universal, and that is the part the launch copy glosses over. GPT-5.5 tops the MRCRv2 long-context test at 94.8 against Fugu Ultra’s 93.6. And the two systems Sakana keeps name-checking as peers, Anthropic’s Fable 5 and Mythos Preview, sit outside the pool entirely because they are export-controlled and not publicly accessible. On Sakana’s own framing, Fable 5 actually leads SWE-Bench Pro, the very benchmark Fugu Ultra wins among the accessible models.
Three caveats deserve to be loud. First, every number here is vendor-reported by Sakana. Second, the baseline scores for competitors come from each provider’s own published figures, which means the comparison runs across different harnesses and effort settings. Third, the SWE-Bench Pro run used the mini-swe-agent scaffolding, which shapes results.
The defensible reading is that Sakana Fugu is credibly in the frontier conversation on its own numbers, and that an orchestrated pool can plausibly match or beat any single model it contains. Whether it matches the models it cannot contain is a claim to hold loosely until independent evaluations land. If you are making a production decision, run the two or three benchmarks that resemble your actual workload on a representative slice of your own traffic. That beats any leaderboard.
The Export Control Angle: Why Sakana Fugu Launched Now
The timing was not an accident. On June 12, 2026, Anthropic’s most capable models, Fable 5 and Mythos Preview, became subject to national-security-based export controls, and access vanished overnight for organizations across a broad set of countries. Teams that had built critical workflows on those models woke up locked out.
Ten days later, Sakana Fugu shipped with a pitch built directly around that event. The argument, in Sakana’s words, is that relying on a single company’s APIs for critical infrastructure, finance, or governance is a material vulnerability, and that this risk stopped being hypothetical. Because Sakana Fugu orchestrates swappable agents, the claim goes, it can route around a provider that disappears. Sakana frames this as the resilient blueprint for what it calls AI sovereignty.
There is a real point in here. Single-vendor dependency genuinely is an operational risk. Anyone who has had a model deprecated, rate-limited, or repriced mid-project knows exactly what that costs. A diverse, swappable pool is a sensible hedge.
But the sovereignty pitch carries three asterisks the marketing skips, and ignoring them would be dishonest.
The hedge still rents its intelligence. Sakana Fugu routes around the loss of any one provider, but its capability is the pool, and the pool is other companies’ models reached through their APIs. A broad restriction, not a single one, shrinks the pool. Resilience here comes from diversity, not independence.
The terms-of-service question is unresolved. Orchestrating and reselling access to third-party proprietary models through one endpoint sits in a grey zone of each provider’s usage terms. That is a contractual question every adopter inherits.
And it benchmarks against what it cannot use. The systems Sakana Fugu claims to stand shoulder-to-shoulder with are precisely the ones excluded from its pool. Matching them is a claim about substitutes, not a route to their actual output.
None of that sinks the idea. It just means the resilience is softer than the headline implies.
Sakana Fugu Pricing and Access
Sakana Fugu is sold two ways, and the structure is friendlier than I expected.
Subscriptions suit individuals and daily hands-on work. There are three tiers: Standard at $20 per month for light use, Pro at $100 per month with ten times the Standard allowance, and Max at $200 per month with twenty times. Every tier includes both Fugu and Fugu Ultra. Sakana is also dangling a free second month at your initial tier if you subscribe before the end of July 2026, which is a clean incentive to test it during the launch window.
Pay-as-you-go targets heavier production workloads. For Fugu, you pay the standard rate of whichever underlying model handled the request, and Sakana says it does not stack fees when multiple agents are active. You get charged a single rate based on the top-tier model involved, so adding agents does not multiply the bill. Fugu Ultra carries fixed pricing on the fugu-ultra-20260615 snapshot: $5 per million input tokens and $30 per million output, rising to $10 and $45 once context passes 272K, with cached input at $0.50. That output rate sits in premium frontier territory. Heavy Ultra tasks have reportedly reached around $10 per message, which adds up fast on high-volume pipelines.
The hard constraint is geographic. Sakana Fugu is not available in the EU or EEA at launch while the company works toward GDPR compliance. For European operations, that makes it a non-starter today, which is a real irony given how much of the sovereignty argument is aimed at exactly the regulated buyers those rules protect.
What Early Users Are Actually Building
Sakana ran a beta with close to 500 early users, and the patterns that came back are more telling than the benchmark grid.
A software engineer reported that Fugu Ultra surfaced more than twenty issues in a code review where other frontier models flagged roughly three. A security engineer noted that, given one scoped instruction, Fugu ran a full assessment end to end, recon through XSS and SQLi checks, auth review, and a clean report with evidence and retest steps, all while staying inside scope and avoiding destructive actions. An enterprise executive pointed at something subtler: persona stability. Fugu held its identity across long sessions where other models drift, which matters enormously for agent products running multi-hour tasks.
The most striking case was AutoResearch. Running in a near-fully automated research mode on a single H100 GPU over roughly fourteen hours, Fugu Ultra ran 123 experiments improving a small model’s training recipe, finishing with the best mean bits-per-byte at 0.9774, ahead of three anonymized frontier baselines. It planned experiments, ran them, interpreted failures, revised its approach, and kept making progress with little human input. That is not a polished demo. That is the long-horizon agentic behavior people have been waiting on, and it is exactly what the deeper pool is built for.
The Honest Criticisms: What to Check Before You Ship
Most launch coverage stops at the highlight reel. A senior team should not. None of the following is a reason to dismiss Sakana Fugu, but each is a question to answer before you route customer-facing work through it.
Pool composition is opaque. The single sharpest criticism in the developer community is that Fugu is a closed orchestrator partly leaning on closed model APIs, and Sakana has not disclosed the ratio of open to closed models behind its benchmark scores. Since the system’s performance depends heavily on that pool, the opacity is a fair complaint.
Benchmarks are unverified. Every figure is a vendor self-report. Independent evaluation is the gate, not the launch post.
Cost and latency can fan out. When a request touches several models, both the bill and the response-time distribution can widen. The single-top-tier-rate policy softens cost, but model your real workload rather than the cheapest path.
Observability gets murkier. When a model picks the models, you give up some control over which system produced which answer. Confirm how granular the usage attribution is before you depend on it for audits or debugging.
And there is a concentration irony worth sitting with: adopting Sakana Fugu to reduce vendor dependency adds a new dependency on Sakana’s orchestrator. That can still be a net win, but it is a trade, not an escape. Some early users also reported launch-day site errors, which suggests the rollout was a little rushed.
Sakana Fugu vs DIY Orchestration: When to Reach for It
The bigger signal is not this one product. It is that model orchestration is now a category you can buy rather than only a pattern you build. It sits alongside three approaches teams already use: aggregator-style routing, do-it-yourself frameworks like LangGraph and CrewAI, and the in-harness dynamic workflows that model vendors ship themselves.
Reach for a hosted orchestrator like Sakana Fugu when your workload spans coding, reasoning, and research, you value top-end answer quality over deterministic control, and you are comfortable with a managed black box. Route it yourself when you have a known task mix, tight cost targets, and a team that can own routing logic and observability, since that keeps the orchestration in your codebase where you can audit it. And just use one strong model when the task is narrow and well served, because a single frontier model is the easiest thing to price, reason about, and debug.
For most operators this week, the move is not to rip out a working stack. It is to register that orchestration matured into a product, and to add Sakana Fugu to the short list you benchmark against your own traffic when single-model quality plateaus. If you track the broader shift, our coverage of [the AI export controls reshaping model access](INTERNAL: AI export controls Fable Mythos) and [how multi-agent systems are evolving in 2026](INTERNAL: multi-agent AI systems guide) gives the wider context.
Frequently Asked Questions
What is Sakana Fugu?
Sakana Fugu is a multi-agent orchestration system from Tokyo-based Sakana AI, launched June 22, 2026. It presents as a single OpenAI-compatible model API, but internally it is a language model trained to call a pool of other LLMs, and instances of itself, coordinating them to solve complex tasks. You send one request, and Fugu decides whether to answer directly or assemble a team.
How is Fugu different from a model router like OpenRouter?
A router maps requests to models using rules you define. Sakana Fugu learns its routing. It is a trained model that decides delegation, agent communication, and synthesis on its own, including recursive self-calls, rather than following hardcoded if/else logic. The orchestration lives inside the model, not in your code.
Is Sakana Fugu better than Opus 4.8, GPT-5.5, or Gemini 3.1 Pro?
On Sakana’s own benchmarks, Fugu Ultra leads several coding and reasoning tests against those publicly accessible models, though GPT-5.5 still tops the MRCRv2 long-context test. All baseline scores are provider-reported and not independently verified, so treat the comparison as a vendor self-report until third-party evaluations arrive.
How much does Sakana Fugu cost?
Subscriptions run $20, $100, and $200 per month, all including both models, with a free second month for sign-ups before the end of July 2026. Pay-as-you-go Fugu Ultra is $5 per million input tokens and $30 output, rising to $10 and $45 above 272K context. Heavy Ultra tasks have reportedly hit around $10 per message.
Can I use Sakana Fugu in the EU?
Not at launch. Sakana Fugu is unavailable in the EU and EEA while the company works toward GDPR and EU-specific compliance. It is available in much of the rest of the world, though access can vary by local regulation and network conditions.
What does “route around export controls” mean, and is it safe to rely on?
It means that if one provider in the pool becomes inaccessible, Fugu can shift work to the others. It is a genuine hedge against losing any single vendor, but the capability still depends on third-party models reached through their APIs, so a broad restriction would shrink the pool. Treat it as resilience through diversity, not true independence.
Ved Vyas
Writer at Fable Knows, covering AI and the technology shaping everyday life.
Related stories.

Seedance 2.5: 5 Powerful Upgrades Confirmed for July 2026
Seedance 2.5 is confirmed: ByteDance revealed 30-second clips, 50 reference inputs, and an early July launch. See every upgrade and what it means. (154…
GPT-5.5-Cyber: 7 Powerful Upgrades Beating Mythos 5 in 2026
OpenAI’s GPT-5.5-Cyber model just took back the security crown, and the fixing pipeline matters more than the score. On June 22, 2026, OpenAI stopped…