GPT-5.5-Cyber: 7 Powerful Upgrades Beating Mythos 5 in 2026
OpenAI’s GPT-5.5-Cyber model just took back the security crown, and the fixing pipeline matters more than the score.
On June 22, 2026, OpenAI stopped pretending the hard part of cybersecurity was finding bugs. The hard part is fixing them. That single reframing is what makes the full release of GPT-5.5-Cyber matter more than its benchmark scores, and the scores are already loud enough to start a fight.
Here is the short version before the detail. OpenAI expanded its Daybreak program with the complete version of GPT-5.5-Cyber, a rebuilt Codex Security plugin, a new Daybreak Cyber Partner Program, and an open-source rescue mission called Patch the Planet. The model now posts the highest single-model CyberGym score OpenAI has ever recorded. And quietly, on that same benchmark, GPT-5.5-Cyber edged past Anthropic’s Mythos 5. That last part is the story almost nobody is putting in the headline.
What GPT-5.5-Cyber Actually Is
GPT-5.5-Cyber is a specialized, more permissive variant of GPT-5.5 built for one job: serious, authorized defensive security work. The first preview, released to vetted organizations back on May 7, mostly existed to cut down on annoying refusals. Security engineers were tired of a general model treating “analyze this malware sample” like a request to commit a crime.
This full release goes much further than refusal-trimming. It keeps GPT-5.5’s general intelligence and long-task stamina, then layers on the ability to chew through huge codebases, trace whether a vulnerable function is actually reachable, validate the issue in a controlled environment, write a patch, test that patch, and hand a human reviewer clean evidence. The point is not to flood your inbox with more findings. The point is to walk the whole remediation loop end to end.
OpenAI is not handing this out freely, and that is deliberate. GPT-5.5-Cyber stays inside a limited release for verified defenders working under the Trusted Access for Cyber program. For most teams, OpenAI still recommends plain GPT-5.5 with Trusted Access plus Codex Security as the starting point. The cyber-tuned model is reserved for people whose authorized work genuinely needs more capability and more permissiveness, paired with stronger verification, monitoring, scoped controls, and review.
If you have been tracking how labs gate their strongest reasoning systems, this mirrors the access tiering we covered in our breakdown of [the latest frontier model releases](INTERNAL: GLM-5.2 benchmarks). Capability is no longer the only lever. Who gets to touch it is becoming just as important.
The Benchmark Numbers Worth Memorizing
Benchmarks are not the whole truth, but they set the conversation, so let me lay them out plainly.
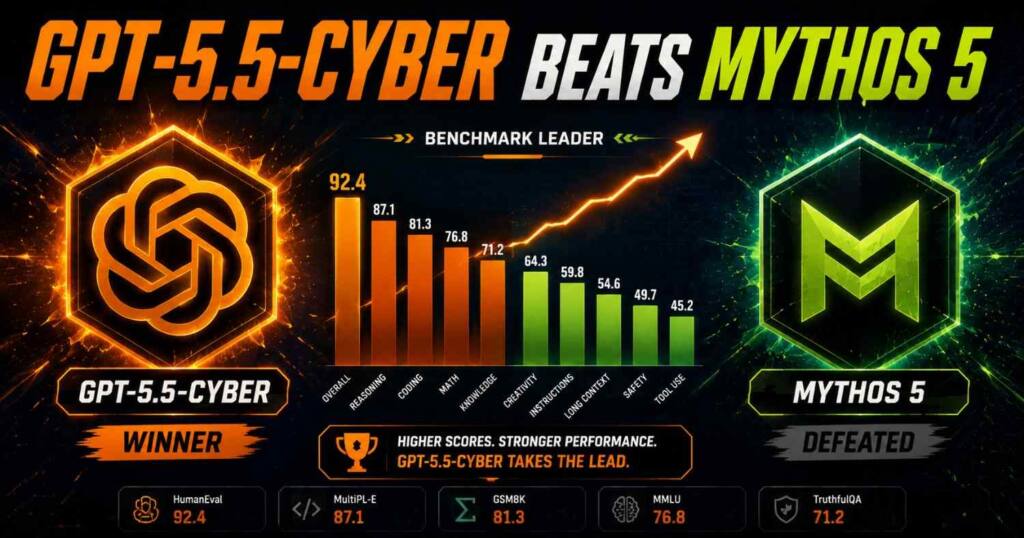
On CyberGym, which checks whether an agent can reproduce known vulnerabilities inside real software environments, GPT-5.5-Cyber reached 85.6% in single-model evaluations. Standard GPT-5.5 sits at 81.8%. OpenAI calls this the highest CyberGym result it has measured from any single model, and that wording matters because it is a direct shot across the bow at the competition.
The gap widens on the harder tests. On ExploitGym, which measures whether an agent can turn a known vulnerability into a working exploit that achieves unauthorized code execution, GPT-5.5-Cyber hit 39.5% against 25.95% for GPT-5.5. On SEC-bench Pro, which evaluates long-horizon vulnerability discovery and proof-of-concept generation across complex targets, it scored 69.8% versus 63.1%.
Read those three together and a pattern jumps out. The harder and longer the task, the bigger the lead GPT-5.5-Cyber opens over its parent model. That is the profile of a system tuned for deep, patient work rather than quick wins, and it is exactly what defenders dealing with sprawling legacy code have been asking for.
The Mythos 5 Showdown Nobody Is Headlining
Here is the angle most coverage is tiptoeing around. Back in April and May, Anthropic’s Claude Mythos Preview was the model everyone whispered about in security circles. It completed a full corporate-network attack simulation end to end before anyone else. It surfaced a 27-year-old vulnerability in OpenBSD that human reviewers had walked past since roughly 1998. On early CyberGym charts, Mythos hovered around 83%, narrowly topping both GPT-5.5 and the first GPT-5.5-Cyber preview.
The full GPT-5.5-Cyber at 85.6% changes that scoreboard. Polymarket and several AI trackers flagged it within hours: OpenAI’s new model now beats Mythos 5 on CyberGym. OpenAI’s own announcement chart, notably, leaves Mythos off entirely, which is its own kind of tell. When you are ahead, you name your rival. When the lead is fresh and fragile, you let the number speak and move on.
I would not over-read a single benchmark. CyberGym measures vulnerability reproduction, not the patient codebase archaeology that made Mythos famous. A model can win the reproduction race and still lose the discovery race that finds a 27-year-old ghost in production. But the symbolism is real. For most of 2026, Anthropic owned the “scariest cyber model” narrative. GPT-5.5-Cyber just took it back, at least on the metric OpenAI chose to publish.
Codex Security: From Alerts to Actual Fixes
The model gets the headlines. Codex Security is the part that changes daily work.
OpenAI shipped an update to the Codex Security plugin that drops defensive workflows straight into Codex, the company’s coding environment. You can scan an entire codebase, a single folder, or one specific commit. It generates reports with severity ratings, affected code locations, validation evidence, and remediation guidance. It traces attack paths, builds a threat model (or invents one if your team never wrote it down), validates findings, and produces codebase-specific patches for review. Results export cleanly into existing vulnerability management systems through SARIF files and CodeQL queries.
The scale figures explain why this matters. Since the March research preview, Codex Security has scanned more than 30 million commits across over 30,000 codebases. Human reviewers manually marked more than 70,000 findings as fixed, and over 500,000 findings were automatically determined to be fixed. OpenAI frames it simply: put the equivalent of a security engineer next to every developer.
The honest caveat is that auto-determined fixes and human-confirmed fixes are different animals. Half a million automatic determinations is a big number, but the 70,000 a human actually signed off on is the trust-worthy one. Still, the direction is unmistakable. The work is shifting from generating alerts that pile up in a backlog to closing tickets that actually ship.
Patch the Planet and the Open-Source Problem Nobody Funds
This is the piece I find most interesting, partly because it tackles a problem money usually ignores.
Open-source software runs the internet, public services, developer tooling, and chunks of critical infrastructure. A flaw in one widely used networking library can ripple into thousands of downstream systems. Yet research from the Linux Foundation and Harvard found that 94 percent of the widely used projects it studied had fewer than ten developers responsible for more than 90 percent of the code added in a year. Translation: the digital world leans on a handful of exhausted volunteers.
AI makes that worse before it makes it better. When models can find vulnerabilities at machine speed, maintainers drown in reports, many of them low-quality false positives. More findings with no extra hands to fix them is not help. It is a denial-of-service attack on volunteer attention.
Patch the Planet is OpenAI’s answer, built with Trail of Bits and in collaboration with HackerOne and Calif. The structure is the clever bit. Trail of Bits engineers run Codex Security and GPT-5.5-Cyber across projects, but every AI-generated finding gets manual review, deduplication, and severity reassessment before a maintainer ever sees it. Maintainers set their own priorities and disclosure rules first. The humans absorb the noise so the volunteers get only validated, ready-to-act work.
More than 30 open-source projects have committed, with early names including cURL, Go, Python, Sigstore, pyca/cryptography, aiohttp, NATS Server, freenginx, and python.org. The first engagement put dedicated engineers across 19 projects. A single five-day sprint surfaced hundreds of issues, merged dozens of patches with more underway, and built reusable fuzzing, variant-analysis, differential-testing, and specification-based testing workflows that maintainers keep using after the sprint ends. Participating projects also receive ChatGPT Pro, conditional Codex Security access, and API credits for development and release automation.
That last detail, the reusable workflows, is what separates this from a one-time charity drive. You can patch a project once and walk away, or you can leave behind tooling that keeps catching bugs. OpenAI chose the second.
The Partner Program and the Geopolitics
OpenAI is not pushing raw model access to the whole world. The Daybreak Cyber Partner Program threads GPT-5.5 with Trusted Access for Cyber into the products of established security firms instead. The partner roster reads like a who’s who of the industry: Accenture, Akamai, Cisco, Cloudflare, CrowdStrike, Darktrace, Fortinet, IBM, Okta, Palo Alto Networks, SentinelOne, Sophos, Tenable, Wiz, and Zscaler, among others. Customers get the model’s defensive muscle through tools they already trust, while direct access stays in vetted hands.
Then there is the government layer, which is where this stops being a product launch and starts being policy. In the past month OpenAI established Trusted Access for Cyber partnerships with Australia, Canada, France, Germany, Japan, the Republic of Korea, and EU institutions like ENISA, plus a deepening relationship with the UK government. Domestically, OpenAI cites continued collaboration with the Center for AI Standards and Innovation on pre-deployment testing, and work with the Office of the National Cyber Director and OSTP on implementing the recent executive order on advanced AI security.
This is the same logic Anthropic used with Project Glasswing a month earlier: keep frontier cyber capability inside a controlled circle of governments and trusted defenders. Two of the biggest labs independently landing on near-identical access models tells you something. Nobody wants to be the company that handed an open-source super-exploiter to the entire internet.
Why This Release Is Bigger Than a Model Update
Step back from the benchmark scoreboard and the real shift is structural. For years the cybersecurity bottleneck was discovery, because finding serious vulnerabilities demanded rare expertise and patience. AI dissolved that bottleneck. Now defenders are buried under more findings than they can possibly triage, and the choke point moved to patching.
A vulnerability report on its own protects no one. Value shows up only when someone validates the issue, understands its blast radius, writes and tests a fix, coordinates disclosure, and helps teams deploy. GPT-5.5-Cyber, Codex Security, and Patch the Planet are aimed squarely at that second, harder half of the loop. OpenAI is no longer selling AI cybersecurity as a benchmark result. It is selling an operational pipeline that scans, validates, fixes, and reviews across enterprise, government, and open-source code.
Whether it delivers is a question only the next few months of real coordinated disclosures will answer. Benchmarks can be gamed. Production codebases cannot. But the thesis underneath GPT-5.5-Cyber is sound, and it is the right thesis: the model that finds the bug is worthless until something lands the fix.
What This Means If You Run a Security Team
Most readers will never get direct access to GPT-5.5-Cyber, and that is fine, because the practical takeaways do not require it.
First, the access tier tells you where to start. If you are not a verified defender under Trusted Access for Cyber, your realistic on-ramp is standard GPT-5.5 with Trusted Access plus the Codex Security plugin. That combination already covers scanning, validation, attack-path tracing, and patch generation for code you own. GPT-5.5-Cyber is the heavier tool for teams whose authorized work genuinely demands more permissive behavior.
Second, watch the partner program rather than the model. If you already buy from Cisco, CrowdStrike, Cloudflare, Palo Alto Networks, or any of the other Daybreak partners, the capabilities behind GPT-5.5-Cyber may reach you through products you already run, without you ever touching the raw model. That is the path OpenAI clearly prefers, and it is the one most enterprises will actually travel.
Third, treat the benchmark wins as a ceiling signal, not a buying decision. GPT-5.5-Cyber topping Mythos 5 on CyberGym tells you the capability frontier moved. It does not tell you the model will fix your specific legacy monolith. Pilot it on a non-critical repo, measure how many of its patches survive human review, and only then trust it on the systems that matter.
The honest summary: GPT-5.5-Cyber raised the bar for what a defensive model can do, but your wins will come from the pipeline around it, the human review, and the boring discipline of verifying every patch before it ships.
Frequently Asked Questions
Who can use GPT-5.5-Cyber? Only verified defenders inside OpenAI’s Trusted Access for Cyber program, working on authorized cybersecurity tasks. It is not generally available. For most teams, OpenAI recommends standard GPT-5.5 with Trusted Access plus Codex Security instead.
How does GPT-5.5-Cyber compare to Mythos 5? On the CyberGym benchmark, the full GPT-5.5-Cyber scored 85.6%, edging out Anthropic’s Mythos 5, which had previously led at around 83%. Mythos still holds a reputation for deep discovery work, like its 27-year-old OpenBSD finding, so the lead depends heavily on which benchmark you weight.
What is Patch the Planet? An OpenAI initiative built with Trail of Bits, HackerOne, and Calif to fix vulnerabilities in widely used open-source software. Human engineers review every AI-generated finding before maintainers see it, so volunteers get validated patches rather than automated noise. More than 30 projects, including cURL, Python, and Go, have committed.
Is GPT-5.5-Cyber dangerous in the wrong hands? That is exactly why access is gated. The model is more permissive for authorized defensive work but still blocks offensive misuse like credential theft and malware deployment, and it is wrapped in monitoring, scoped controls, and government-level testing through CAISI.
What is Codex Security? A plugin inside OpenAI’s Codex environment that scans codebases, validates findings, traces attack paths, generates patches, and exports results in formats like SARIF and CodeQL. Since March it has scanned over 30 million commits across more than 30,000 codebases.
GPT-5.5-Cyber is the loudest number in this release, and reclaiming the CyberGym crown from Mythos 5 will dominate the chatter. But the more durable story is the pivot from finding to fixing. OpenAI built a model that beats its rivals on the scoreboard, then surrounded it with the unglamorous plumbing that actually closes vulnerabilities at scale. That combination, capability plus a working remediation pipeline plus tight access control, is what turns a benchmark win into real-world risk reduction.
You can read OpenAI’s full announcement in its official Daybreak post. And if you want the wider context on how the frontier labs are racing each other on security, our coverage of [Anthropic’s competing cyber strategy](INTERNAL: Claude Fable 5 and Mythos access) tracks the other side of this fight.
Ved Vyas
Writer at Fable Knows, covering AI and the technology shaping everyday life.
Related stories.

Seedance 2.5: 5 Powerful Upgrades Confirmed for July 2026
Seedance 2.5 is confirmed: ByteDance revealed 30-second clips, 50 reference inputs, and an early July launch. See every upgrade and what it means. (154…
Sakana Fugu: 7 Powerful Facts About the Orchestration Model
Explore Sakana Fugu, the 2026 orchestration model that routes around export controls. Get Fugu vs Fugu Ultra benchmarks, pricing, and who should use it.…